Evaluation Metrics For Summarization
Everyone wants GenAI, but no one wants to spend time on evaluation or generating reference texts.
I worked on a summarization project recently but I have never spent time evaluating the summarization output. My summarizer balobi.info makes a lot of mistakes: sometimes it generates news in English, other times it confuses Congo and Rwanda, or sometimes it makes up stuff. Those errors could have been avoided if I had spent time evaluating the metrics and deciding which metrics I could use for my model.
Recently I documented myself on summarization metrics and I found a load of them online. I decided to summarize them for the reader in this post.
Definition
Text summarization is the process of producing a concise and coherent summary while preserving key information and meaning of the source text. There are two major approaches to automatic text summarization: extractive and abstractive summarization. Extractive summarization involves selecting important sentences or phrases from the original document. On the other hand, abstractive summarization generates the summary with sentences that are different from those in the original text while not changing the ideas. In most cases, when you prompt a Large Language Model (LLM), it generates an abstractive summary of the text.
Evaluation
Evaluation is the process of evaluating the quality of a summarization output. Evaluation of a summarization can be done in two ways: by using a human evaluator or using automated metrics. Human evaluation is more accurate but it is time-consuming and requires a lot of effort. Automatic evaluation is simple, easy to scale, but sometimes less accurate.
Human Evaluation:
In most cases, humans are tasked to evaluate the model outputs using four criteria:
- Coherence: It evaluates how good the sentences are.
- Consistency: The factual alignment between the summary and the summarized source. A factually consistent summary contains only statements that are entailed by the source document. Annotators were also asked to penalize summaries that contained hallucinated facts.
- Fluency: The quality of individual sentences. Drawing again from the DUC quality guidelines, sentences in the summary ‘‘should have no formatting problems, capitalization errors or obviously ungrammatical sentences (e.g., fragments, missing components) that make the text difficult to read.’’
- Relevance: Selection of important content from the source. The summary should include only important information from the source document. Annotators were instructed to penalize summaries that contained redundancies and excess information.
A final score is computed by averaging the scores of all these criteria.
Automatic Evaluation:
In term of automatic evaluation we have two types of metrics, references based metrics and non reference metrics. or references free metrics.
References metrics involves a human annotator who will give a reference summary to compare the generated summary against. For non references metrics there is no references and the generated summary is compared against the original text.
Metrics for References Evaluation:
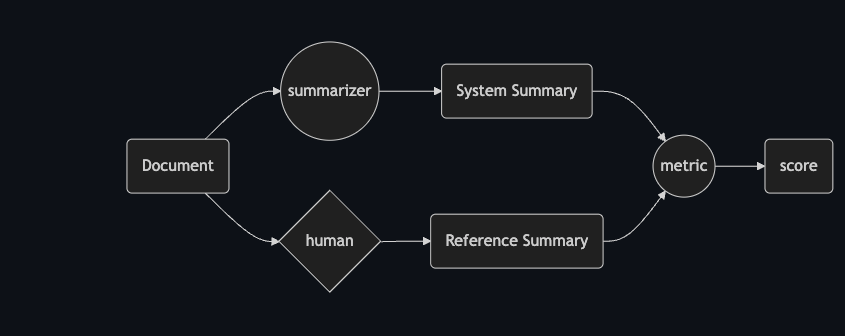
Here are the metrics for automated summarization evaluation:
- ROUGE: (Recall-Oriented Understudy for Gisting Evaluation), measures the number of overlapping textual units (n-grams, word sequences) between the generated summary and a set of gold reference summaries. Many papers have suggested that ROUGE metrics is the one that correlates the most with human juggement.
- ROUGE-WE: extends ROUGE by using soft lexical matching based on the cosine similarity of Word2Vec embeddings.
- BertScore: computes the semantic similarity scores by aligning generated and reference summaries on a token-level. Token alignments are computed greedily to maximize the cosine similarity between contextualized token embeddings from BERT.
- BLEU: is a corpus level precision-focused metric that calculates n-gram overlap between a candidate and reference utterance and includes a brevity penalty. It is the primary evaluation metric for machine translation. CIDER: computes {1–4}-gram cooccurrences between the candidate and reference texts, down weighting common n-grams and calculating cosine similarity between the n-grams of the candidate and reference texts.
Reference Free Metrics:
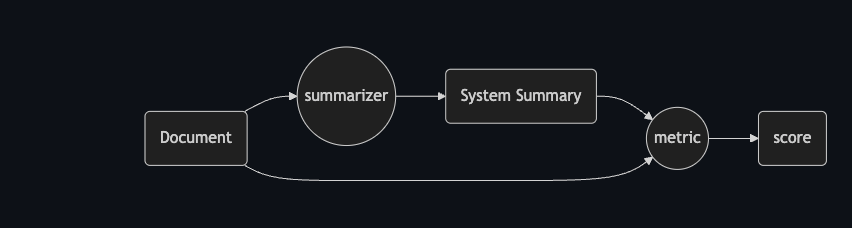
Non reference based metrics are metrics that are based on the matching between the generated summary and the reference text.
They are faster to implement as they don’t requires any human annotator.
All the methods references metrics can be used to build references free metrics. We can do that by considering the original document as the summary and compare the generated summary with it.
- ROUGE-C: is a modification to ROUGE: Instead of comparing to a reference summary, the generated summary is compared to the source document. We can go further with ROUGE C and create metrics that will down-weight common terms in the text and up-weight important terms that are present in the summary. Researchers found that ROUGE-C correlated well with methods that depend on reference summaries, including human judgments.
- SUPERT: Rate the quality of a summary by measuring it semantic similarity with a pseudo reference summary. The pseudo references are generated by selecting salient sentences from the sources document using contextualized embedding and soft token alignment techniques. Compared to the state-of-theart unsupervised evaluation metrics, SUPERT correlates better with human ratings by 18- 39%.
- Entailment Metrics Based on NLI Tasks
Entailment metrics are based on the natural language inference (NLI) task where a hypothesis sentence is classified as entailed by, neutral, or contradicting a premise sentence. To evaluate abstractive summarization for consistency, we check if the summary is entailed by the source document. In the scientific literature the metric used is called SummaC.
How does SummaC works?
It split the original document in block of text(sentences, or paragraph), the generated summary by the sentences. Then use a NLI model such as BERT to compute the entailment score for each sentence of generated summary vs each sentence in the original document. Those scores are saved in a matrix which is called entailment matrix. For SummaCZS, they reduce the entailment matrix into a one-dimensional vector by taking the maximum value in each column. Intuitively, this results in retaining the score for the document sentence that provides the strongest support for each summary sentence. Then, to get a single score for the entire summary, they simply compute the mean of the vector. There are other sophisticated approach of the entailment matrix using a convolutional layer. The bellow picture describes how the entailment matrix works. Cite[8]

LLM as a Judge for summaries Evaluation
With the rise of LLM, we have seen case in the literature where we are using LLM as a judge to evaluate the LLM summary. With this approach we let the LLM is trying to replicate the work a human evaluator.
Evaluating using a Language Model
Unlike metrics like ROUGE or BERTScore that rely on comparison to reference summaries, the gpt-4 based evaluator assesses the quality of generated content based solely on the input prompt and text, without any ground truth references. This makes it applicable to new datasets and tasks where human references are not available.
Here’s an overview of this method:
- Using the four criteria used by human, coherence, consistency, fluency, and relevance.
- Create a prompt that will ask the LLM to generate a score form 1 to 5 for each of those criteria using chain of thought generation.
- We generate scores from the language model with the defined prompts, comparing them across summaries.
Note that LLM-based metrics could have a bias towards preferring LLM-generated texts over human-written texts. Additionally LLM based metrics are sensitive to system messages/prompts. Sometimes you don’t have an LLM available for evaluation and you need to stick to traditional metrics.
Conclusion
In this post, we highlight evaluation methods for summarization, discuss the different types of summarization evaluation, and show the pros and cons of each method. The right metrics for your summarization project depend on the engagement of your stakeholders. When they are engaged, ask them for reference summaries and fine-tune your prompts to obtain good metrics using the reference texts. Alternatively, you can ask them to evaluate different summaries generated by various prompts and different LLMs. If there is no engagement from the stakeholders from the beginning, prefer reference-free metrics.
Sources:
- Liu Y, Iter D, Xu Y, Wang S, Xu R, Zhu C. (2023). G-EVAL: NLG Evaluation Using GPT-4 with Better Human Alignment.
- Zhang T, Kishore V, Wu F, Weinberger KQ, Artzi Y. (2020). BERTScore: Evaluating Text Generation with BERT.
- Lin CY. (2004). ROUGE: A Package for Automatic Evaluation of Summaries.
- Fabbri A, et al. (2021). SummEval: Re-evaluating Summarization Evaluation.
- Yan, Ziyou. (2023). Evaluation & Hallucination Detection for Abstractive Summaries.
- He T, et al. (2008). ROUGE-C: A fully automated evaluation method for multi-document summarization. 2008 IEEE International Conference on Granular Computing, Hangzhou, China, pp. 269-274. doi: 10.1109/GRC.2008.4664680.
- SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization (Laban et al., TACL 2022)
Comments