Agentic Customer Service Agent System Design
In this post I will describe how I answer a take home test for an AI Engineer Role.
Assignment: Design a context‑engineering architecture for a multi‑turn customer support AI agent. Format: Take‑home (3-5 days) + 10‑minute presentation.
Problem Statement
You are building an AI agent for a financial services organization to support customers across multiple product lines (credit cards, loans, investments, insurance). The agent must:
- Maintain coherent multi‑turn conversations (10–20+ turns)
- Retrieve and reason over ~50,000 policy documents and FAQs
- Integrate with APIs to fetch customer account information
- Escalate when confidence is low or risk is high
- Meet regulatory constraints: auditability, safety, and no hallucinated financial advice
Design:
System Goals:
- Automatically resolve more x % of the issues, x is the metric to discuss with the business, to start we can say 50-60%
- Reduce (mean time to resolution) of the ticket.
- Zero hallucination: Abstain when incertain, it is better to route multiple questions to the agent than to give hallucinated answers to the users.
- Don’t give false information
- Redirect to human in case of any error.
- Hand of accuracy, summarize before sending to the Human Agent
- Latency SLA:
- P50 < 90 seconds (typical case)
- P95 < 150 seconds (complex queries)
- P99 < 180 seconds (worst case acceptable) (this is a metric to discuss with the business)
- Anytime we route a conversation to a human, we should provide him with context such as conversation history and all the step the model have taken to try to solve the problem up to the point where it was routed to human.
Scope
- Chat interface, (not voice now)… with an AI agent to figure out the resolution. Bonus we can also add a mail handler.
- Understand the context of the question and respond accuracy(context retrieval)
- Ask Clarifying questions
- Check similar issues that have already been answered.
- Tool execution : Fetch information from database and from user in formation -> RAG
- Track the sentiment and the urgency if we can route to humans for quicker resolution.
- Callback functionality if human is not available right away.
- Track observability metrics (Evals, observability)
Guardrails
- PII masking
- Never authorize high refunds / credits /discount > 100 USD without approval from humans.
- Finite loop - prevent excessive intent loops if unresolved routes to humans.
- Tone consistent to give higher customer experience.
- The agent should not perform any interaction write to the user database.
Agent Architecture:
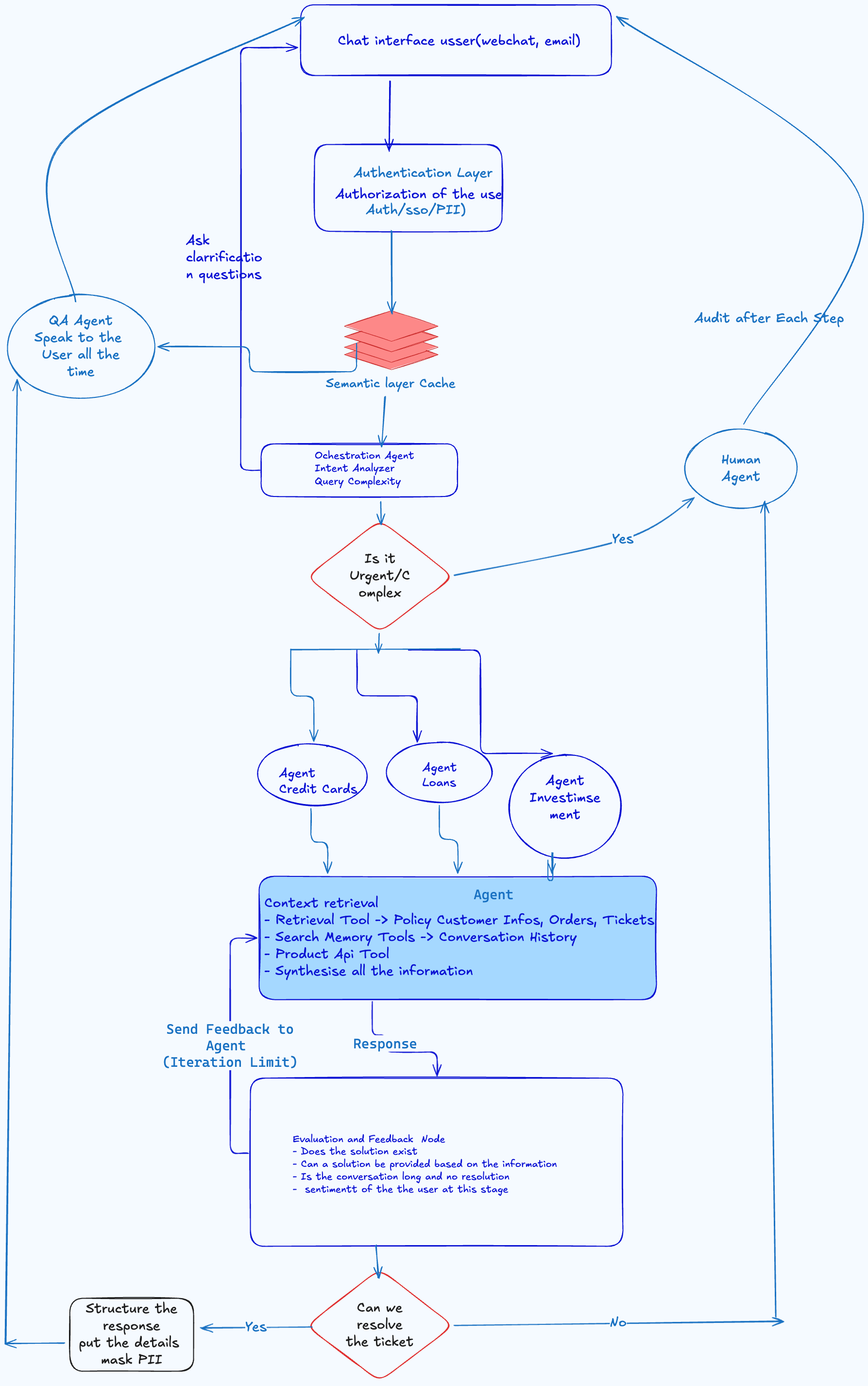
The system will be built with different components, the next post will describe the component of the system:
Authentication Component:
Check and authenticate the user to make sure only authorized users can use the system.
First Component : Semantic Cache
In this component save user queries for frequently asked questions, we can update it every 90 days with Frequently asked questions.
In terms of Technology: Redis or Postgres(yes Postgres can also be used as Cache). We will save the question and their vector representation.
Orchestration Component
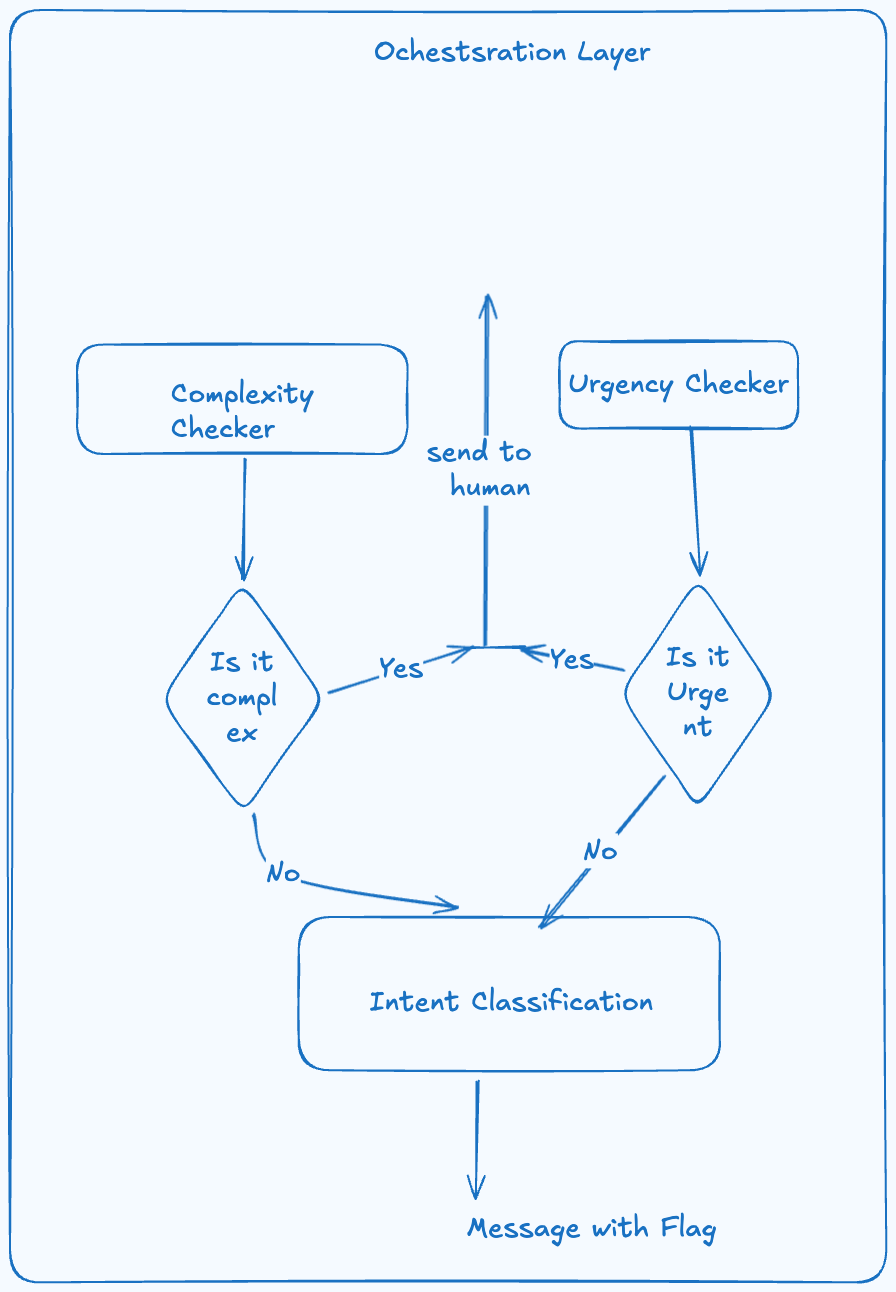
The second Component of our architecture will be the orchestrator component.
For this we will use semantic routing and we will have 3 different small text classifications models.
The first two checks will run in parallel: Complexity and Urgency. Complex and urgent queries should be routed to the agent.
If they pass they will go to an intent classification model which classifies the intent in 3 categories we are handling. Each product line will have a different category, credit cards, loans, investments, insurance, etc.
Model to use: Bert type model for text classification trained and fine tuned on our dataset. Avoid using a LLM here for cost optimization and context.
The output of this phase will be a text with its intent, given the intent the text will be routed to the appropriate agent. Note if the question has two intent in it, we will consider it as two separate questions and handle each question differently in parallel.
From a technical perspective, delegating tasks to specialized agents is one of the most effective ways to manage context window bloat.
If a query passes this step it will be routed to the appropriate agent for conversation generation
The Agentic Component
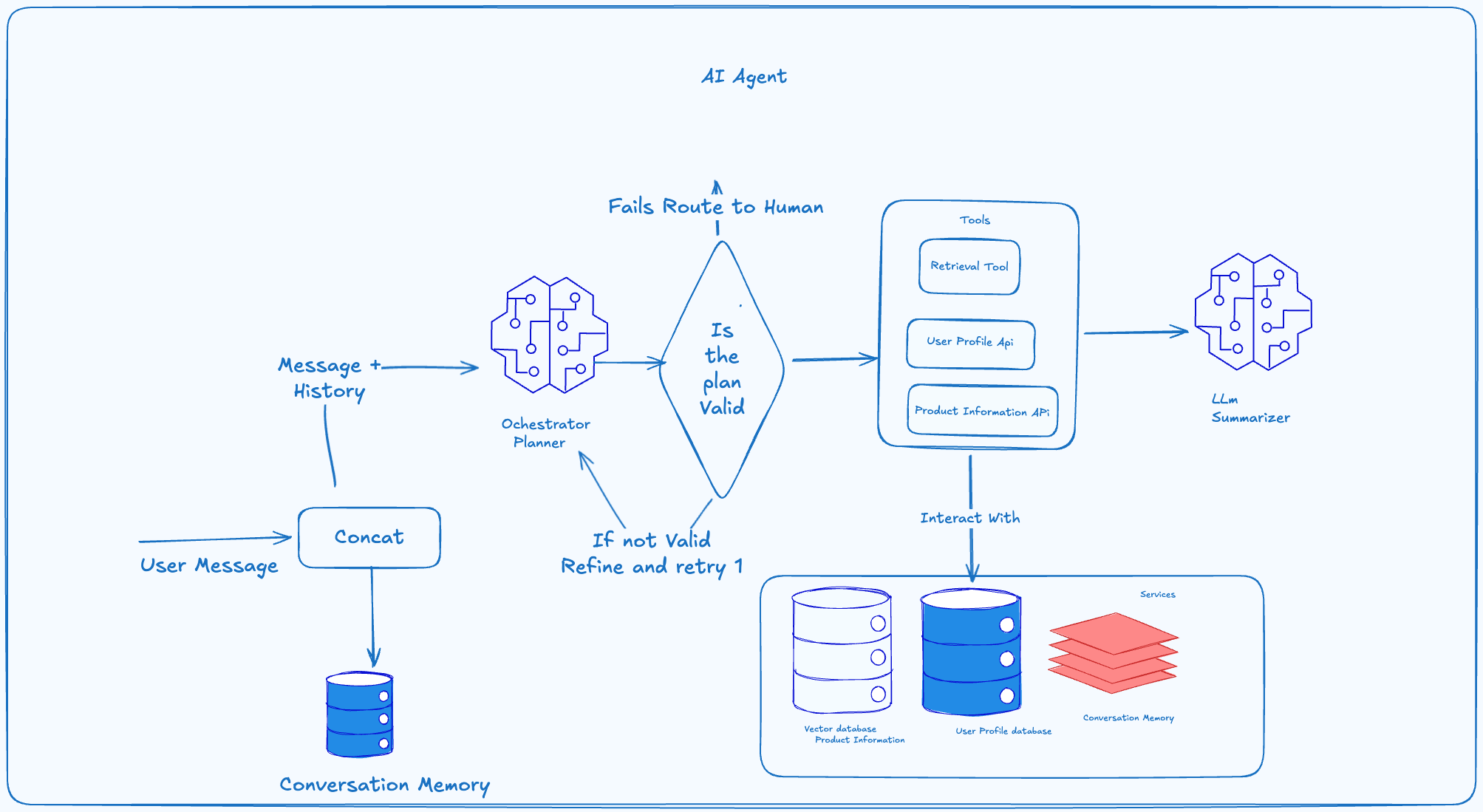
This will start first by checking the conversation history to build the context of the question, then ask the LLM to generate a plan to answer the question given the conversation history. After the plan is generated it will be validated, if it fails we can refine it 2 to 3 times and then if it fails we will return the question to the human agent.
The execution of the plan can be done by either the user api or the RAG system.
Components:
- LLM(Planner/Orchestrator): A model with function tooling and reasoning capabilities, try a model from the gemini family.
- Also later to reduce latency we can try small models: A research has shown that they are performing better. Small Language Models for Efficient Agentic Tool Calling: Outperforming Large Models with Targeted Fine-tuning.
Plan Validation:
For the plan validation we can use a role based validator to check :
- All actions in plan are available in the tools.
- Plan has less than 4 steps.
- No circular dependencies between plans.
Tool Execution Strategy:
The planner generates a DAG indicating dependencies.
Example Plan:
{action: "get_user_infos", depends_on: []},
{action: "fetch_product_infos", depends_on: []},
{action: "generate_query", depends_on: ["get_user_infos", "fetch_product_infos"]},
{action: "generate_response", depends_on: ["generate_query"]}
]
Execution:
1. Run get_user_infos() and fetch_product_infos() IN PARALLEL
2. Wait for both to complete
3. Run generate_query() with both outputs
4. Run generate_response()
This reduces latency when tools are independent.
Prompt Template for the Planner:
You are a customer service agent planner, Propose a plan a DAG (directed acyclic graph) to answer the user message You have access to 4 actions:
* get_user_infos()
* fetch_product_infos()
* generate_query(task_history, tool_output)
* generate_response(query)
The plan must be a sequence of valid actions.
- Tools with no dependencies run in parallel
- Tools with dependencies run sequentially
Examples
Task: "Can you tell me about your recent product information? "
Plan: [[get_user_infos||generate_query], generate_response]
Task: "What was the best selling product last week?"
Plan: [get_user_infos, generate_query, generate_response]
Task: {USER INPUT}
Plan:
If you fails to generate a plan return a I cannot generate the plan.
Constraint:
Tools:
The model have access to 3 functions:
- Get_user_profile_info
- Search_product
- generate_answer.
After each step we will save the results in a logging database for traceability.
Conversation Memory:
- Postgres database-
- RAG memory Postgres with PGVector
In the conversation memory we will be saving the summarized version of the user interaction with the system. We will use the following prompt to summarize them:
```
Summarize this customer support conversation into key facts:
- Customer identity and account details
- Main issue/request
- Actions taken so far
- Current status
Conversation: {old_turns}
Summary (max 200 words): ```
RAG Architecture
This is the architecture that will perform the search:
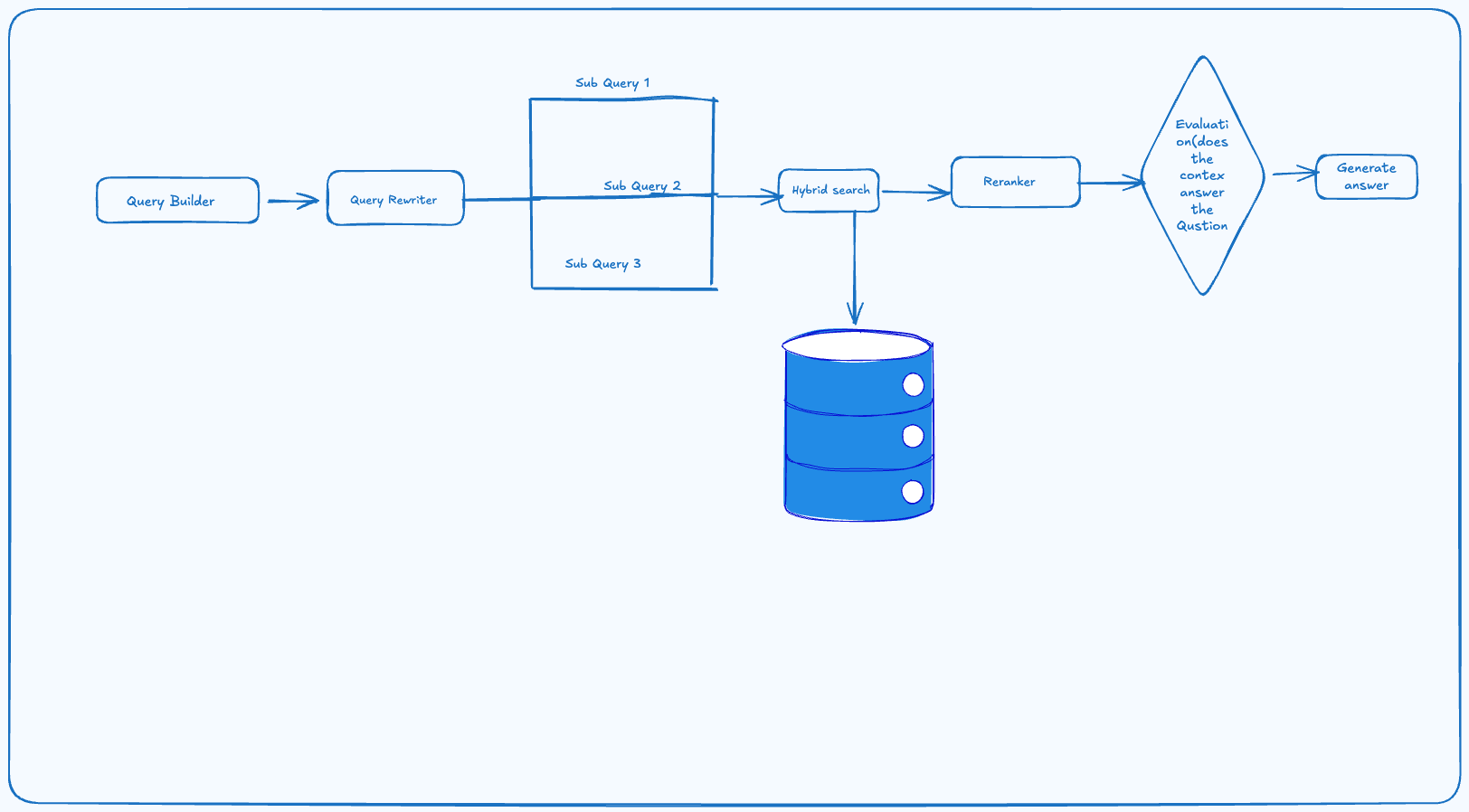
Query builder, we will use an LLM to decompose the user query in multiple subqueries and keywords to facilitate search. For each subqueries we will perform parallel search and keyword search using BM25. We will aggregate the results and use the text with a re-ranker. First evaluation check will be to check with the LLM if it can ask the question given the context. If we fails, we route the question to the agent with the information we have.
Models to use:
- Embedding models Qwen Models
- Reranker: Jina Models But we can benchmark those models here.
RAG prompt Template
You are a powerfull customer service agent
Given the user Query the conversation history and the following context,
generate the answer to the query question,
if you can’t generate the answer given the context return I don’t have answer to the question.
When you can generate the answer return the list of citation where you found it.
Note on Memory Design
- Short-term memory: Redis (semantic Cache)
- Long-term memory: Postgres for finding similar past conversations, plus a regular database for storing user preferences and facts.
Evaluation and Guardrails
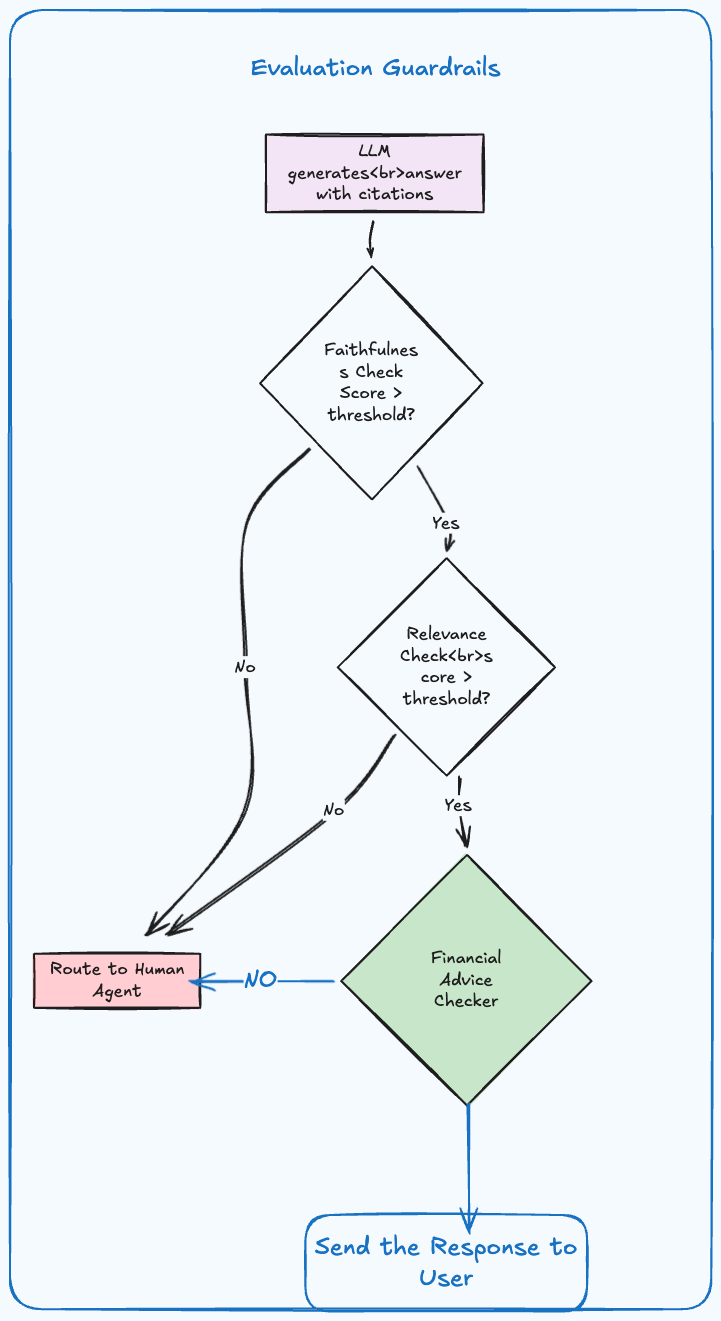
- Faithfulness is the method to check if the answer is not hallucinated, it helps us to check if the answer is supported by the context. For this we can use a Natural Language Inference model or LLM as a Judge. Answers that fail this check will be routed to the human agent with validations. We check the Faithfulness between the answer and the chunk used to generate it.
- Answer Relevancy: Check if the answer is relevant to the question. This will help us to check if the answer we generated really addresses all aspects of the question. Again a failure here we will route the answer to the agent but with context. For this an embedding model that compute the cosine similarity between the question and the answer can be useful otherwise LLM as Judge
- Check for Financial Advice: We can use a Financial advice detector to detect if the answer contains any financial advice.
A simple sentence classification model can be useful here. The model can be trained on a custom dataset of financial advice and non financial advice. The threshold for the guardrail will be adjusted after evaluation and discussed clearly with the business.
More on Evaluation here, it is a blog written by me.
Trade-off Analysis
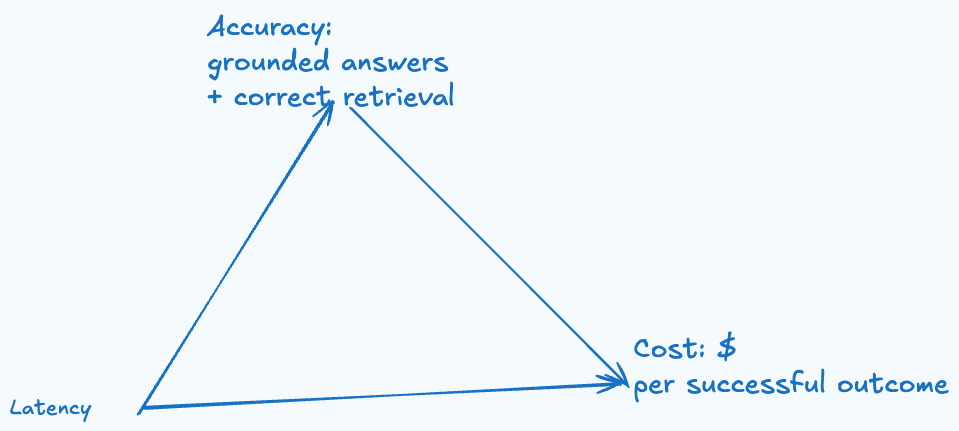
We cannot pick all the 3, we can only pick 2.
-
Accuracy + Latency → Cost goes up You add: rerankers, query rewriting, multi-stage retrieval, more evals, more calls.
- Accuracy + Cost → Latency goes up You accept slower flows: stricter gating, extraction-first, better versioning, more checks.
- Latency + Cost → Accuracy is constrained You go cache-heavy, link-first answers, templates, smaller models, fewer steps.
The more complicated we go on the agentic the less fast our system will be.
For this application we will compromise a little bit on latency and focus more on Accuracy and cost.
Additional Features
Logging and monitoring: After each component we will log the results in a NoSQl database. We will also track major escalation issues and those will help to improve the system with time. PII handling we will hide PII before any external LLM call, before saving the logs.
Unanswer Questions:
Model choice for each time System design for the database and the whole application Maximum token per component.
References
References
[1] Google Cloud. “Choose a Design Pattern for an Agentic AI System: Coordinator Pattern.” Google Cloud Architecture Center. Google Cloud Architecture Center
[2] Weng, L. (2023, June 23). “LLM-powered Autonomous Agents.” Lil’Log.
[3] Chip, H. (2024, July 25). “Building a Generative AI Platform.” Chip Huyen’s Blog.
[4] Microsoft. “Agentic RAG.” AI Agents for Beginners Tutorial Series.
[5] Reddit Discussion. “POV: RAG is a Triangle - Accuracy vs Latency vs Cost.” r/Rag, 2024.
[6] arXiv:2507.13334. “Small Language Models for Efficient Agentic Tool Calling: Outperforming Large Models with Targeted Fine-tuning.”
[7] Reddit Discussion. “AI Agent Memory That Doesn’t Suck: A Practical Guide.” r/AI_Agents, 2024.
Comments